
30 years of PHP
What to Consider on the Technical Side
Technical SEO
Search engine optimization is an essential part of web development. In addition to many other aspects, SEO also includes a technical level to optimize your online presence. We give an overview, which possibilities on the technical side exist, in order to optimize the own ranking in search engines.

Search engine optimization, SEO for short, has become an essential part of modern web development. The focus is almost always on content, which makes perfect sense, because "content is king". However, the fact that you can also improve your ranking on a technical level is often neglected. In this article we describe some of the most important aspects that you can use to make crawling and indexing easier for the search engines and thus improve your ranking.
1. Meta Tags #
Admittedly, meta tags also receive attention in most content-focused SEO efforts. Essential tags like the page title or description are almost always included. However, these are by no means all the meta tags that can and should be set. The following tags should also be considered:
Robots #
With the robot tag, robots, such as the Google bot, can be controlled individually per page. Not only the indexing (index/no-index) or the following of links on the page (follow/no-follow) can be controlled, but also a variety of other things. Some examples are:
- noarchive - do not cache the page. Controls whether a page may be stored in the internal cache by the search engine and loaded and displayed from there when needed, instead of directing users to the web page
- nosnippet - do not show text or video preview of the page in search results
- notranslate -do not show automatic translation in search results
- noimageindex - do not index the images on this page
- unavailable_after - do not show the page in search results after this point of time
More information on this topic can be found here: developers.google.com
Canonical #
The canonical tag is especially important when the exact same content is accessible via multiple URLs. By specifying a canonical URL, you can determine under which URL a page should be displayed in the search results.
Alternate & hreflang #
If content is offered in several languages, the alternate tag should be used. This allows the same content to be referenced in a different language and ensures that search engines find and index it optimally. This allows search engines to deliver content directly to the user in the preferred language.
The hreflang attribute, which is placed on links, has the same benefit. Here, too, the robot can be directly informed about the language of the linked content.
2. Structured Data & Rich Search Results #
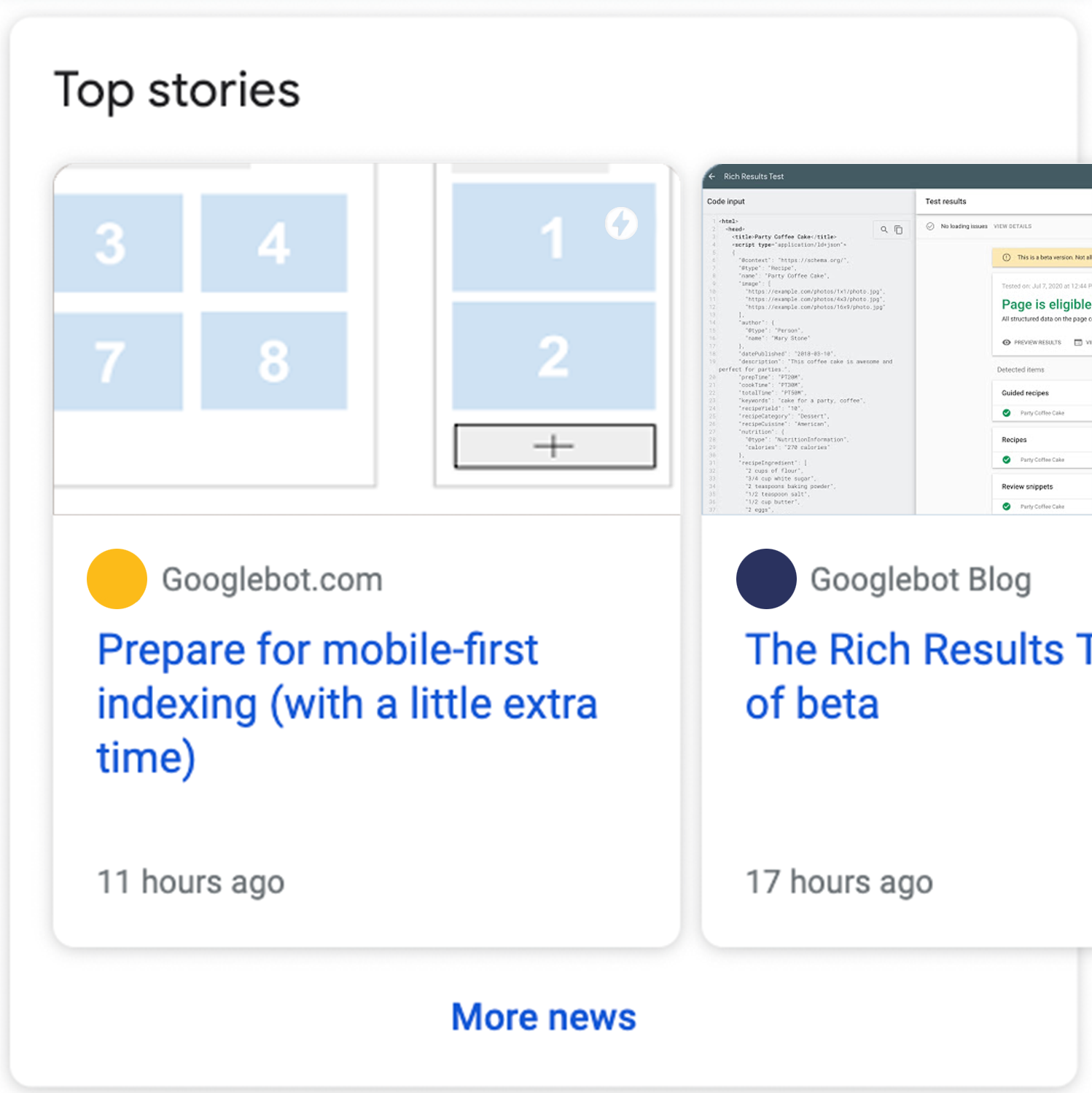
Structured data can be used to help search engines better identify and understand the content of a page. This not only ensures that content is actually indexed and interpreted as it was intended, but is also a prerequisite for content to be displayed as "rich" in search results. These rich search results, as they are called by Google, are optimized forms of presentation for the content, which are particularly attractive and visible to users.
By now, rich search results can be obtained through structured data for a variety of content types. Some examples are: Articles, books, products, reviews, recipes, events but also results like FAQs, logos or voice commands. (for more information follow this link: developers.google.com
Here we show three examples of such search results for articles, events and FAQs:
Source: developers.google.com
3. Robots.txt and Sitemap.xml #
In an article about technical SEO measures, the robots.txt and the sitemap.xml should not be missing.
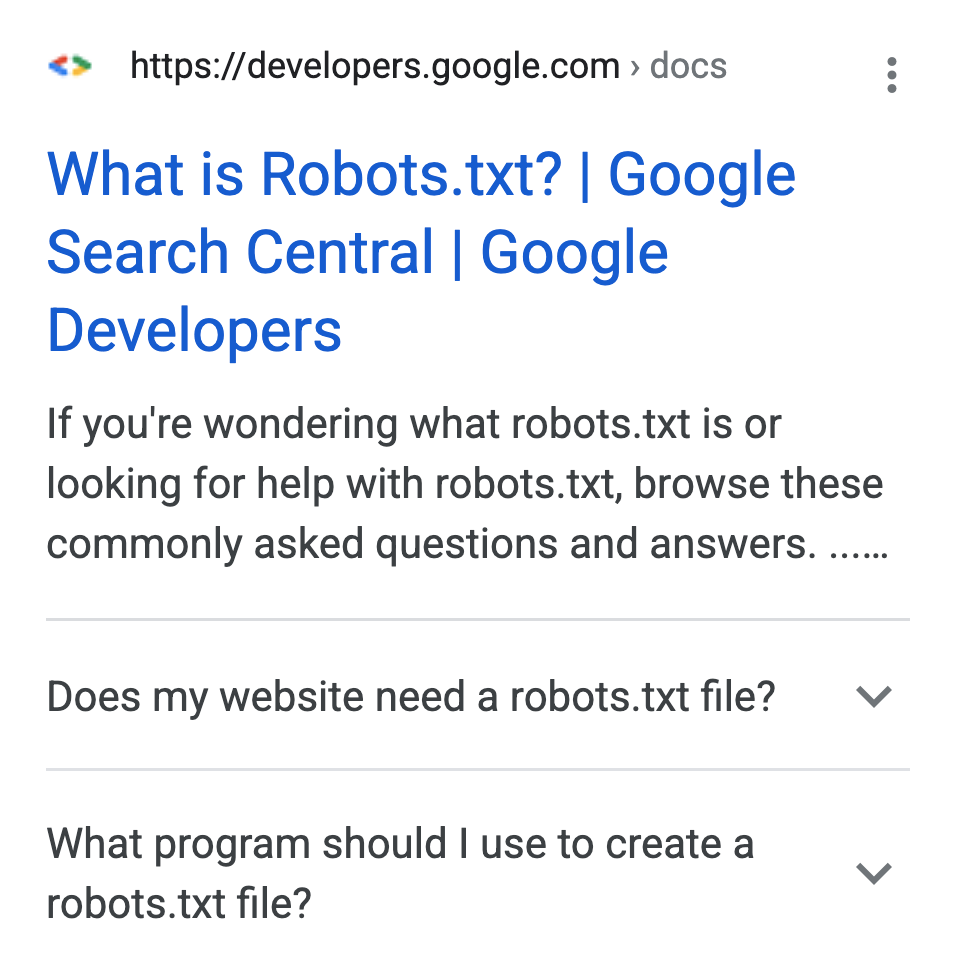
Robots.txt #
With the help of the robots.txt, robots, i.e. the search engines, can be informed which pages they may or may not access. This does not mean, as often assumed, that these pages are excluded from the indexing! For example, if a page is linked on another page, it can happen that the page is included in the index despite the blocking by robots.txt. To exclude an indexation, the Robots Meta Tag is essential. The use of robots.txt is rather to reduce requests from robots or to direct them to the target in a controlled way.
Sitemap.xml #
The sitemap.xml on the other hand is comparable to an address book. In it, all important resources, i.e. pages, images and videos, can be listed that should be included in the search engine index. A sitemap.xml is not necessary, but it makes sense to create one anyway, because it ensures that all resources can be found. The sitemap.xml can also be submitted directly to many search engines, which - especially for new websites - can significantly reduce the time until indexing.
4. Redirects and Status Codes #
Redirects and the correct status codes can also have an influence on the ranking of a website. Redirects are when one URL automatically redirects to another. For example, if the user opens example.com and is redirected directly to example.com/en. For redirects, a basic distinction is made between temporary and permanent redirects. Depending on the type of redirection, the corresponding status code should be output by the server. (A status code is part of the HTTP protocol and provides information about the type of response, for example 404 - Not found).
In the case of redirects, search engines use the status code to decide what to do with the original page. In case of permanent redirects, search results in the future will directly contain the destination URL, moreover, the rating of the page may also be transferred to the destination address. The origin address will disappear from search results. This is especially important for page redesigns or changes to the URL structure in order to soften a drop in ranking.
Temporary redirects, on the other hand, will continue to show up in search results. This redirection can be useful to redirect users from temporarily unavailable content to possible alternatives without causing any impact in the ranking of the original content.
However, status codes are important signals for search engines and robots not only in redirects. There are also adequate status codes in other scenarios, such as content that is not (or no longer) available or services that are currently unavailable. If, for example, in the case of missing content, not the correct status code is set, this symbolizes for search engines that actual content is offered under the URL. As a result, this URL appears in the search results.
5. Accessibility & Semantics #
Search engines like Google evaluate pages primarily on the basis of their usefulness for users. This concerns both content and usability. For the latter, accessibility plays an important role. In order for assistive technologies, such as screen readers, to be able to handle content, some technical details are crucial. These include, for example, the use of semantic HTML, setting titles and alternative text attributes, the use of so-called ARIA tags, but also things like font sizes, contrasts and spacing between elements. Equally relevant are factors such as responsiveness and page loading speed.
Conclusion #
There are many details to consider when it comes to search engine optimization. Not only in terms of content, but also on a technical level, modern websites must stand out in order to achieve a top ranking in the search results. In this context, it is important to keep an eye on all current requirements and to stay up to date at all times. We are at your service as a reliable partner for technical SEO.
-
 Author Jürgen Fitzinger, MSc
Author Jürgen Fitzinger, MSc
 Michaela Mathis
Michaela Mathis